DHRS Medical Assistance System
A course project website for EECS 349 Machine Learning at Northwestern University
And an artificial intelligent system caring for your health, completely free of charge :)

A course project website for EECS 349 Machine Learning at Northwestern University
And an artificial intelligent system caring for your health, completely free of charge :)
JianXu2020@u.northwestern.edu
RongqiDing2020@u.northwestern.edu
The health and medical care industry is an industry of great importance and intricacy and we would lime to make the medical system more accessible to the non-professionals, and at the same time, reduce the heavy work load placed on the professionals. What we’re looking forward to establish is a tool which takes patients’ symptoms (typed in words) as inputs and gives basic diagnose as outputs. A tool like this can be of great use. Patients can use it to get an idea of the potential explanation to their health problems and how severe it is. Doctors and hospitals can use it to assign patients to the most suitable department and reduce the amount of human labor involved.
Our work can be broken down into three major subtasks: “Word Vectorization”, “Feature Extraction” and “Classification”, utiliazing machine laerning approches including "Linear Classification" and "Weighted Nearest Neighbor". The raw input are first preprocessed into vectors using the “bag of words” idea, and then corresponding features (or key words) are extracted separately for every medical specialty (class). In the classification process, output value are assigned by the class whose features are what the test sample is closest to. A weighted distance calculation is used in this process.
Our system achived very promising accuracy on some classes, for example, Allergy / Immunology and Autopsy. Mean while, it performed rather poorly on some classes such as Surgery.We believe that this is due to the inconsistency of the training and testing dataset. The dataset we used is limited and not the most ideal for our task because of the way the input sentences are stuctured. So the keyword we extracted from it is also limited and less ideal. We believe our system can apply to fields beyond medical industry and we plan on testing our system on better suited datasets.
In depth reportFrom 'symptems' to 'the most related medical department'
The raw input is a sentance or two describing the symptons of the paitient in words. For example,
The output we're expecting is the medical department this patient could most likely seek help from. In this case, the output should be
'Preprocess' and 'Bag of Words'
The first thing we need to do to preprocess the raw inputs. After steps such as removing punctuations, regularization, removing stop words, tokenization and lemmatization, a raw input such as "A 23-year-old white female presents with complaint of allergies." will be transformed into a list of words tokens are shown in the picture below.

The next step is to vectorized the list of words, using the "Bag Of Words" theory as shown below. (The is a toy sample, the dimension of our actual vectors are to big for a clear visualization purpose.)

Learning the 'key words' for every medical department
Our goal of feature (or key words) extaction is achieved through linear calssification. Performing a slightly twisted "one-verses-all" classification of all of the exixting department's sample set, we're alble to get hold of the top 15 weighted words for every class, AKA the most important 15 words for every medical departments, and their final weights after the training.
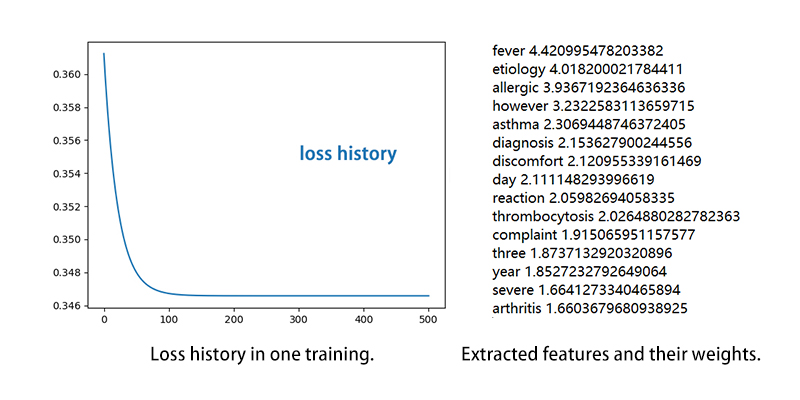
Generate outputs for new inputs.
We use weighted L1 norm to compute the distance between the test sample and the features for every class and save them as a list. Then we use ‘argmin’ to select the smallest label as the output classifications, meanwhile we also output the second smallest and the third smallest labels as candidates.
We normalize all the weights in a symptom to unit length, so the result won't be affected too much if there is a keyword that has a much larger weight that disturb the other keywords. Furthermore, we added regularization across all the calcualte distance for a more reliable result.

Out put of a test sample.